
DeepSeekのV4モデルが重要である3つの理由
DeepSeek V4では何が起きたのか
DeepSeekは[日付を指定]にV4のプレビューをリリースし、これを製品ラインの主力モデルとして位置付けています。このリリースの重要性を正確に枠組みするには、DeepSeekが確立したパターンを理解する必要があります。同社は、オープンソースモデルを継続的にリリースしており、これらは文書化されたパフォーマンス特性を備え、推論操作あたりの計算コストが低い状態で、独占的な代替案に匹敵するか上回るパフォーマンスを実現しています。V4はこの軌跡における主張された進歩を表しており、具体的には2つの側面に焦点が当たっています。拡張されたコンテキストウィンドウ処理と、トークンあたりの推論コスト削減です。
アーキテクチャの主張には具体的な説明が必要です。V4は、シーケンス長に対する計算複雑性スケーリングを削減するアテンションメカニズムの修正を組み込んでいると報告されています。これが検証されれば、トランスフォーマーベースのモデルにおける文書化された制限に対処することになります。標準的なスケール付きドット積アテンションはシーケンス長に対してO(n²)の複雑性を示し、コンテキストウィンドウサイズに実用的な制約を生じさせます。近似アテンションメカニズム(スパースアテンションパターンや低ランク近似など)はこれを準二次複雑性に削減できますが、表現能力における測定可能なトレードオフを伴い、これは経験的に定量化される必要があります。
-
関連性の前提条件:* これが運用上重要なのは、(1)現在のワークフローが既存モデルの実用的な限界を超えるコンテキストウィンドウを必要とする場合、または(2)トークンあたりの推論コストが運用予算の実質的な構成要素である場合のみです。どちらの制約も持たない組織は評価を延期すべきです。
-
検証が必要な仮定:* V4の公開ベンチマークは、あなたの特定のタスク分布でのパフォーマンスを反映しています。標準的な評価スイート(MMLU、GSM8Kなど)は狭い能力帯を測定します。本番環境のワークロードは異なるパフォーマンス特性を示す可能性があります。
-
実行可能なステップ:* 現在のモデルのコンテキストウィンドウ利用率とトークンあたりの推論コストを文書化してください。コンテキスト切り詰めが発生するワークフロー、または推論コストが許容可能なしきい値を超えるワークフローを特定してください。これらが評価候補です。
V4はどのようにしてテキストをより効率的に処理するのか
DeepSeek V4は、拡張シーケンスでの推論中にメモリ消費と計算操作を削減するために設計されたアテンションメカニズムの変種を実装していると報告されています。具体的なアーキテクチャアプローチは技術ドキュメントから明確にする必要があります。予備的なレポートは、(a)隣接していないトークン間のアテンション重みを選択的に計算するスパースアテンションパターン、(b)完全なアテンション行列の低ランク近似、または(c)複数のスケールでコンテキストを圧縮する階層的アテンション構造のいずれかを示唆しています。
各アプローチは異なる含意を持ちます。スパースアテンションは計算を削減しますが、長距離依存性を必要とするタスクでパフォーマンスを低下させる可能性があります。低ランク近似は情報を圧縮しますが、表現ボトルネックを導入します。階層的アプローチは計算を分散させますが、多段階処理からのレイテンシを追加します。
実用的な結果は、あなたの特定のタスク分布での経験的評価を通じてのみ測定可能です。報告されたコンテキストウィンドウサイズ(100K以上のトークン)は容量メトリクスであり、パフォーマンス保証ではありません。モデルは技術的に100Kトークンを処理できますが、そのスケールで出力品質が低下する可能性があります。
-
具体的な制約:* 法務文書処理は、(1)文書が現在のモデルの実用的なコンテキスト限界を超える場合、(2)チャンキング/要約からの品質低下が近似アテンションメカニズムの品質コストを超える場合、および(3)より長いシーケンスを処理するインフラストラクチャコストが現在のチャンキングパイプラインより低い場合にのみ、拡張コンテキストから利益を得ます。
-
検証が必要な仮定:* 報告された効率向上は、あなたの特定のハードウェア構成(GPUモデル、メモリ容量、バッチサイズ)全体で成立します。効率メトリクスはハードウェア依存であり、異なる推論環境間で転送されない可能性があります。
-
実行可能なステップ:* V4の技術ドキュメントを取得し、アテンションメカニズムの変種を指定してください。あなたの実際のハードウェアを使用して、ワークフローから代表的なドキュメントで制御されたベンチマークを実行してください。測定してください:(a)品質低下前の最大コンテキスト長、(b)様々なコンテキスト長でのトークンあたりのレイテンシ、(c)ピークメモリ消費。同じハードウェアで現在のモデルと比較してください。
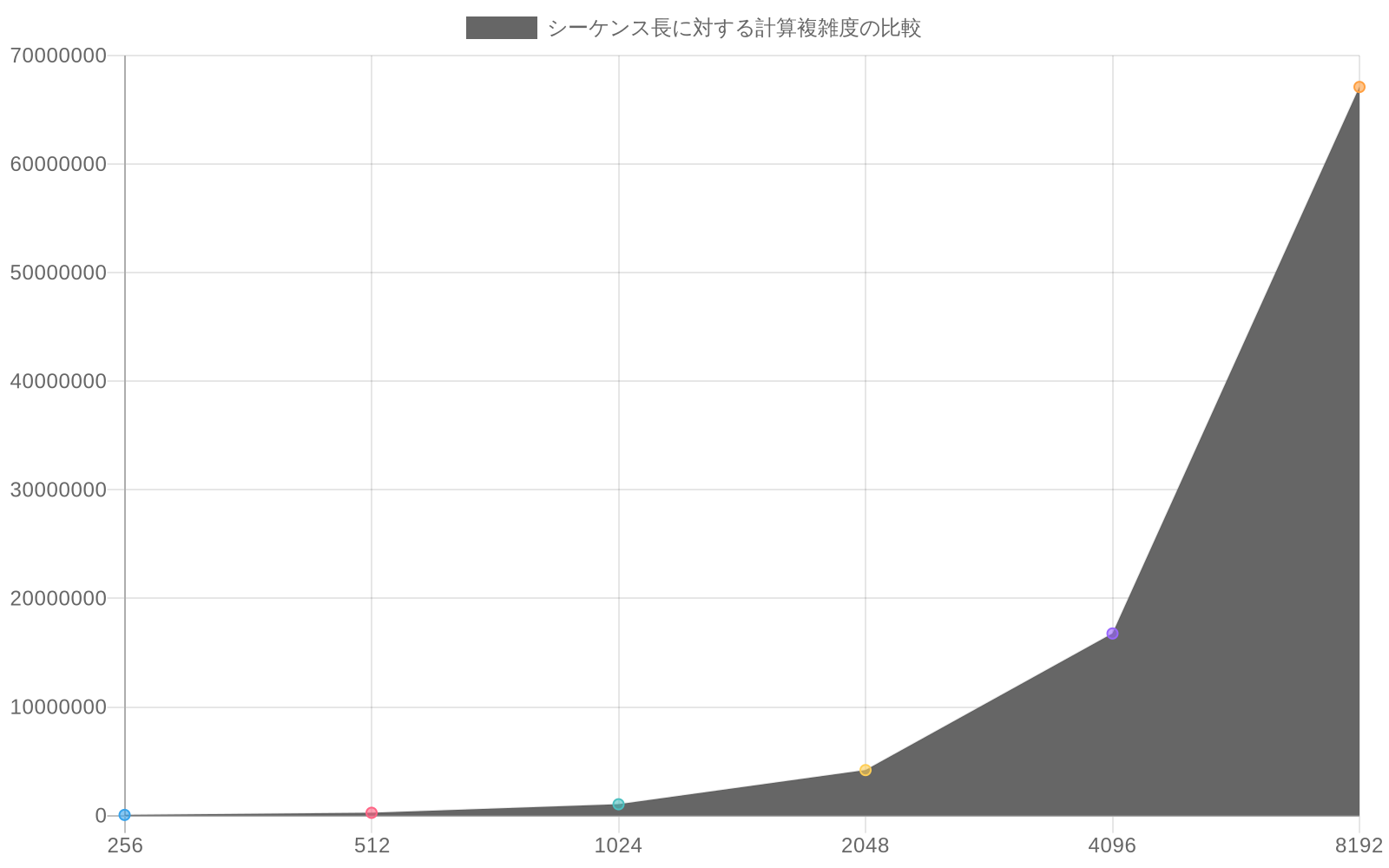
- 図3:シーケンス長に対する計算複雑度の比較(出典:Transformer architecture analysis)*
DeepSeekのオープンソース位置付けが今重要である理由
V4はローカルデプロイメントと商用利用を許可するオープンソースライセンスの下でリリースされています。この位置付けの戦略的重要性は、特定の条件に依存します。V4のパフォーマンス特性が、APIベースの消費に対する自己ホスト型デプロイメントの運用オーバーヘッドを正当化するかどうかです。
オープンソースデプロイメントは運用要件を生じさせます。GPUインフラストラクチャのプロビジョニング、モデルサービングソフトウェア(vLLM、TensorRTまたは同等のもの)、依存関係管理、セキュリティパッチの適用、および監視インフラストラクチャです。これらは固定および変動コストを課します。自己ホスト型の決定は、これらのコストが以下によってオフセットされる場合にのみ経済的に合理的です。(a)APIの価格設定に対するトークンあたりのコスト削減、(b)ローカル処理からのレイテンシ改善、(c)外部データ送信を禁止するコンプライアンス要件、または(d)定量化されたビジネス影響を伴うベンダーロックイン回避。
「オープンソース」と「制約なし」の区別には明確化が必要です。オープンソースライセンスはコード可用性と修正権に対処します。モデル動作の運用制約(安全ガイドライン、拒否パターン)はライセンスに直交し、オープンソースリリースで持続します。自己デプロイメントはこれらの制約を排除しません。ベンダーから運用者への責任を転送します。
-
具体的な制約:* データレジデンシ要件は、(1)コンプライアンスフレームワークが明示的に外部API送信を禁止する場合、(2)自己ホスト型のコストがコンプライアンス承認の独占的な代替案より低い場合、および(3)組織がデプロイメントを維持する運用能力を持つ場合にのみ、自己ホスト型デプロイメントを正当化します。
-
検証が必要な仮定:* オープンソースライセンス条項は、あなたの意図された使用ケースを許可しています。特定のライセンス(Apache 2.0、MITなど)をあなたの組織の法的要件と意図された商用アプリケーションに対して検証してください。
-
実行可能なステップ:* 現在のモデル消費パターンを監査してください。データレジデンシ制約の対象となるワークフローを特定してください。それぞれについて、計算してください。(a)現在のAPIコスト、(b)推定自己ホスト型コスト(GPU償却、人員、インフラストラクチャ)、(c)APIと自己ホスト型アプローチ間のコンプライアンスコスト差分。この分析を使用して評価候補を優先順位付けしてください。
チームが採用すべき運用パターンは何か
V4の自己ホスト型デプロイメントには、APIファースト消費とは異なるインフラストラクチャの決定が必要です。運用モデルは消費ベース(トークンあたりの支払い)から容量ベース(インフラストラクチャ利用率の支払い)にシフトします。これは異なるコスト動力学と障害モードを導入します。
-
インフラストラクチャ要件:*
-
ピークスループット需要に十分なGPU容量
-
モデルサービングフレームワーク(vLLM、TensorRTまたは同等のもの)、あなたのハードウェアでの文書化されたパフォーマンス特性を備えたもの
-
可変需要を管理するためのロードバランシングとリクエストキューイング
-
推論レイテンシ、スループット、エラー率、およびリソース利用率の監視
-
サービス低下のためのフォールバックメカニズム
-
コストモデルの考慮事項:*
-
GPUインフラストラクチャコスト(資本またはクラウドレンタル)を推論ボリューム全体で償却
-
デプロイメント、監視、および保守のための人員コスト
-
電気および冷却コスト(オンプレミスの場合)
-
他のワークロードに利用できないインフラストラクチャ容量の機会コスト
損益分岐点分析には具体性が必要です。1日あたり1000万トークンを処理するチームは、自己ホスト型でより低いトークンあたりのコストを達成する可能性がありますが、(a)GPU利用率が高い(70%以上)場合、(b)インフラストラクチャが完全に償却されている場合、および(c)運用オーバーヘッドが最小限である場合のみです。十分に利用されていないインフラストラクチャまたは高い運用負担はこの計算を逆転させる可能性があります。
-
具体的なパターン:* V4をコンテナ化された環境にデプロイし、キューの深さに基づいてオートスケーリングを実装してください。以下について個別の監視を実装してください。(a)1秒あたりに処理されたトークン(スループット)、(b)最初のトークンまでの時間(レイテンシ)、(c)GPUメモリ利用率、(d)エラー率。これらのメトリクスはしばしば反対方向に動きます。スループットの最適化はレイテンシを増加させる可能性があり、その逆も同様です。
-
実行可能なステップ:* 実際のピークおよび平均スループットを使用してインフラストラクチャコストをモデル化してください。現在のAPI支出と比較してください。デプロイメントと保守のための人員コストを含めてください。この分析を使用して、自己ホスト型がワークロードに対して経済的に正当化されるかどうかを判断してください。
- 図9:ユースケース別V4適用可能性マトリックス(出典:ユースケース分析)*
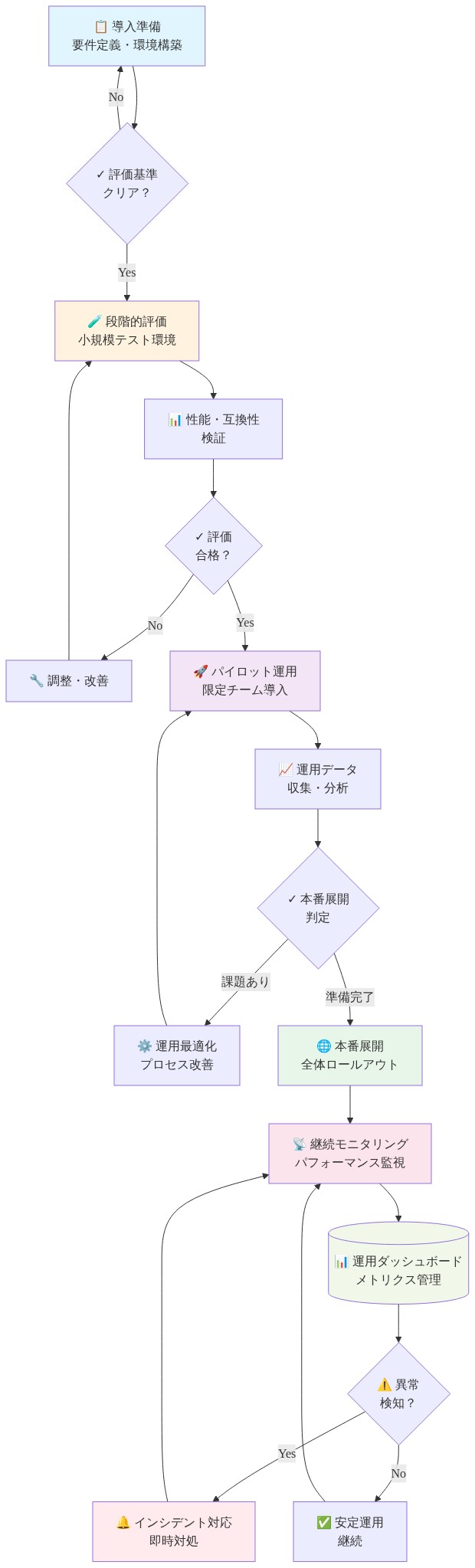
- 図8:DeepSeek V4導入の運用パターン(段階的評価・パイロット・本番展開・モニタリングフロー)*
V4があなたのユースケースにどの程度適合しているかをどのように測定するか
評価には、公開ベンチマークへの依存ではなく、タスク固有のメトリクスが必要です。現在のモデルを使用して実際の本番データで基準パフォーマンスを確立し、同じ入力でV4パフォーマンスを測定してください。
- デプロイメント前に確立するメトリクス:*
-
精度(タスク固有): あなたのユースケースで「正しい」が何を意味するかを定義してください。分類タスクの場合、これは簡潔です(精度、F1、適合率/再現率)。生成タスクの場合、人間による評価基準またはタスク固有のメトリクス(翻訳用のBLEU、事実上の質問用の完全一致など)を確立してください。
-
レイテンシ: 最初のトークンまでの時間(ユーザー向けアプリケーションに関連)と総完了時間(バッチ処理に関連)の両方を測定してください。これらはモデルとハードウェア構成間で大きく異なる可能性があります。
-
コスト: インフラストラクチャ償却(自己ホスト型の場合)またはAPI価格設定(クラウドベースの場合)を含む推論あたりの総コスト、および前処理または後処理のオーバーヘッドを計算してください。
-
評価方法論:*
-
各高ボリュームユースケースから500~1000の代表的な例を使用してください
-
同じ入力でV4と現在のモデルを実行してください
-
各例のすべての3つのメトリクスを追跡してください
-
入力特性(長さ、複雑性、ドメイン)別に結果を分解してください
-
出力の定性的な違い(例えば、幻覚パターン、推論品質)を文書化してください
-
具体的な例:* カスタマーサポートチャットボットの場合、測定してください。(a)精度(応答は顧客の質問に正しく対処しているか)、(b)レイテンシ(最初のトークンまでの時間と総応答時間)、(c)相互作用あたりのコスト。すべての3つの側面でV4を現在のモデルと比較してください。質問カテゴリ(請求、技術サポートなど)別に分解して、V4が優れている場所または劣っている場所を特定してください。
-
実行可能なステップ:* 各ユースケースについて現在のモデルでの基準パフォーマンスを文書化するスプレッドシートを構築してください。2週間V4を並行して実行してください。すべての3つのメトリクスを追跡してください。違いの統計的有意性を計算してください(サンプルサイズが重要です。単一の例は逸話的です)。このデータを使用してデプロイメント決定を通知してください。
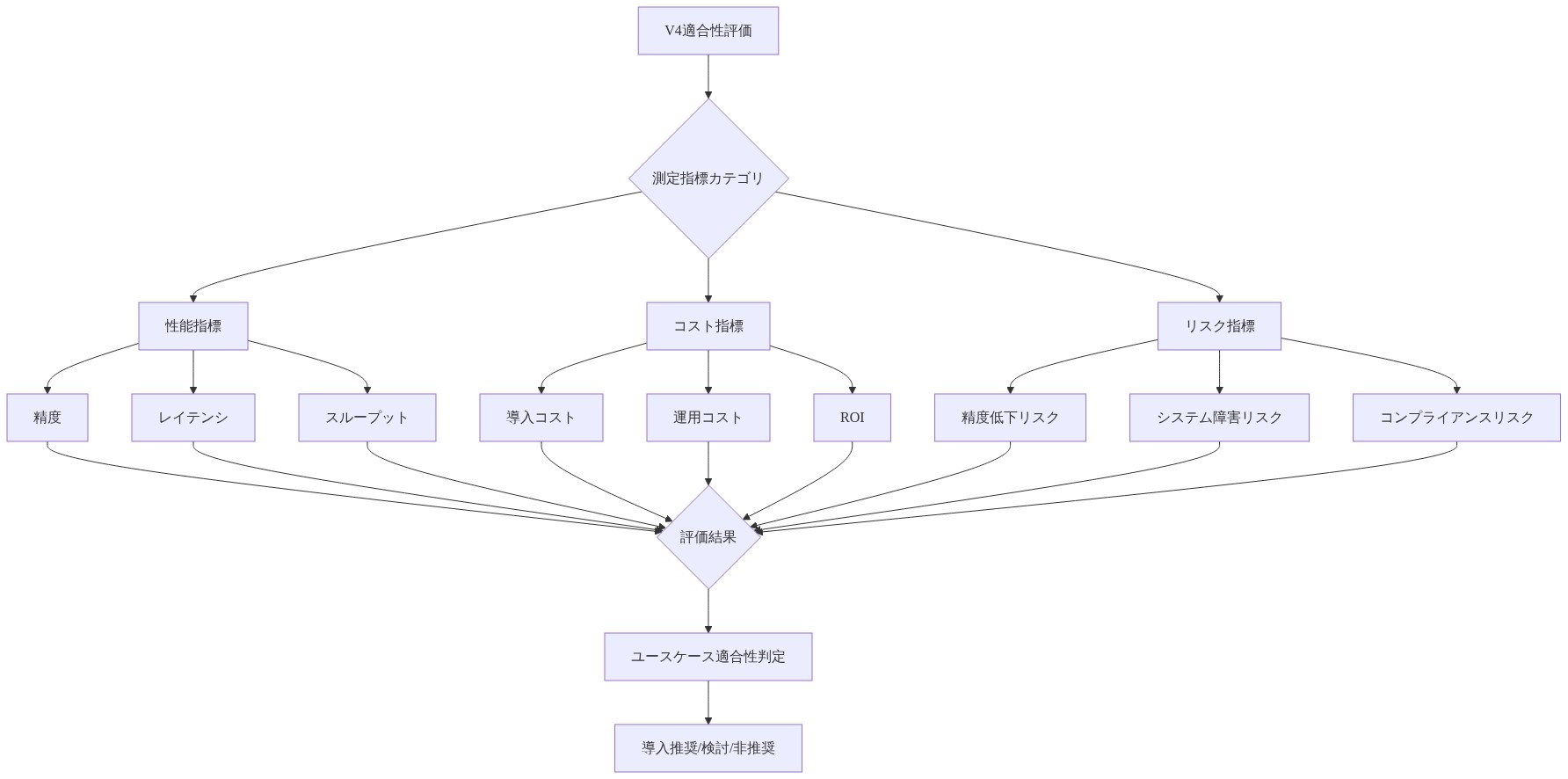
- 図10:V4適合性評価フレームワーク(Evaluation methodology)*
どのようなリスクが軽減を必要とするか
V4は本番環境で硬化した独占的なモデルに対して新しいものです。リスクには以下が含まれます。
-
技術的リスク:*
-
公開ベンチマークに存在しないエッジケースまたは予期しない動作
-
継続的な負荷またはの特定の入力パターンでのパフォーマンス低下
-
既存インフラストラクチャとの互換性の問題
-
オープンソースコードベースの依存関係脆弱性
-
運用リスク:*
-
セキュリティパッチと依存関係の更新の責任
-
インフラストラクチャの信頼性と障害復旧
-
モデルサービングとGPUインフラストラクチャの人員専門知識ギャップ
-
ベンダーサポートの制限(コミュニティ駆動型サポート対商用SLA)
-
軽減戦略:*
-
フォールバック機能を維持してください: V4評価中に現在のモデルを運用し続けてください。V4レイテンシがしきい値を超えるか、エラー率が急増した場合、リクエストをフォールバックモデルにルーティングするサーキットブレーカーロジックを実装してください。
-
段階的なロールアウト: 完全な移行前にV4をトラフィックのサブセット(例えば、10%)にデプロイしてください。拡張前に問題を監視してください。
-
運用準備: デプロイメント、監視、および保守のためのDevOps容量を割り当ててください。一般的な障害シナリオのランブックを確立してください。
-
依存関係管理: オープンソースコードベースの自動セキュリティスキャンとパッチ管理を実装してください。
- 実行可能なステップ:* アプリケーションロジックにサーキットブレーカーを実装してください。レイテンシとエラー率のしきい値を定義してください。V4がこれらのしきい値を超える場合、自動的にリクエストをフォールバックモデルにルーティングしてください。サーキットブレーカーの起動を監視してV4障害のパターンを特定してください。
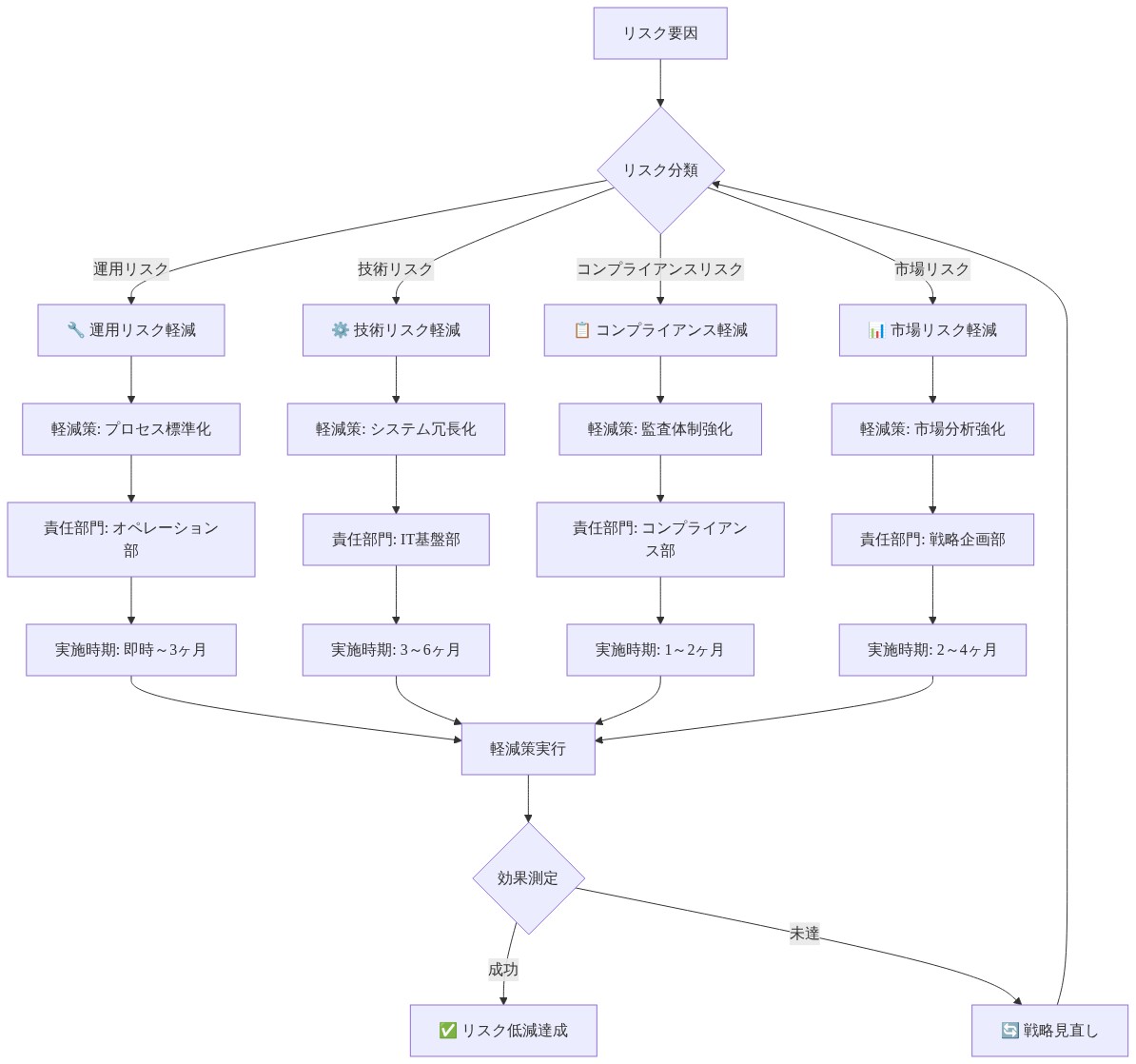
- 図13:リスク軽減戦略マッピング(Risk management framework)*
次に何をすべきか
V4は、オープンソースモデルの能力向上を表していますが、向上はあなたの特定のユースケースへの適合性と同等ではありません。即座のアクションは移行ではなく評価です。
- 優先順位付けフレームワーク:*
- 最高ボリューム、最低リスクのユースケースを特定してください(高トークンボリューム、パフォーマンスが低下した場合のビジネスへの影響が低い)
- 上記で確立されたメトリクスを使用して、このユースケースでV4パフォーマンスを測定してください
- 結果を現在のモデルと比較してください
- データに基づいて決定してください。結果が運用オーバーヘッドを正当化する場合、段階的に拡張してください。結果が混在している場合、V4を特定のワークロード用の特殊なツールとして保持してください。結果が否定的な場合、評価を延期してください
- 拡張基準:* 以下の場合にのみ追加のワークロードをV4に移行してください。(a)初期ユースケースでの評価結果がパフォーマンスしきい値を満たすか超える場合、(b)インフラストラクチャコスト分析が自己ホスト型を正当化する場合、および(c)デプロイメントと保守のための運用能力が存在する場合。
目標は選択肢です。各ワークロードに適切なモデルを選択する能力であり、すべての問題に単一のソリューションを強制することではありません。V4は一部のユースケースに最適であり、他のユースケースに最適ではない可能性があります。公開ベンチマークではなく、実際のワークロードでの評価がこの区別を決定します。
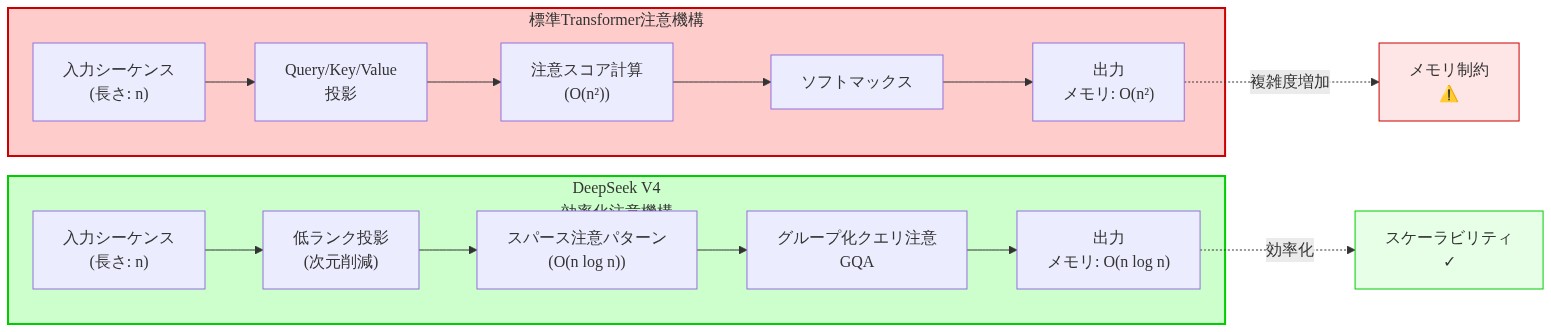
- 図2:標準注意機構 vs DeepSeek V4の効率化メカニズム(Technical architecture comparison)*
- 図14:次のアクション実行ロードマップ(短期・中期・長期の段階的実行計画)*