
構造化EHRファウンデーションモデルにおけるトークン化のトレードオフ
基礎:EHRモデルにおけるトークン化が重要である理由
構造化電子健康記録のためのファウンデーションモデルは、タイムスタンプ付きの臨床イベントの縦断的シーケンスを操作して、一般化可能な患者表現を学習します。これらのシーケンスがモデルアーキテクチャに到達する前に、離散的なトークンに変換される必要があります。このプロセスは、モデルが表現し学習できる情報を根本的に制約します。
トークン化設計は、測定可能な3つの結果を決定します。(1)どの臨床情報が保持または破棄されるか、(2)計算上の制約に対する結果的なシーケンス長、(3)トークン表現に事前計算される時間的・意味的関係とモデルが学習する関係のバランスです。最適でないトークン化スキームは、臨床的に関連のある区別を排除し、利用可能なメモリまたは推論レイテンシ予算を超えるシーケンスを生成し、またはモデルに、トークン設計で明示的であるべき関係を学習するための表現能力を割り当てることを強制する可能性があります。
-
具体例:* 薬剤投与イベントのエンコーディングを考えてみます。粗いスキームは「メトホルミン500mg経口」を単一トークンとして表現し、用量情報を排除するかもしれません。細粒度スキームは、薬剤名、用量の大きさ、用量単位、投与経路、投与時間に対して個別のトークンを作成し、臨床的詳細を保持しますが、シーケンス長を5倍増加させる可能性があります。トレードオフは直接的です。より細粒度のトークン化は臨床的区別を保持しますが、計算コストを増加させ、モデルの注意をより予測性の低いトークン境界に分散させる可能性があります。
-
この分析の前提条件:* 下流タスク(例えば、再入院予測、有害事象検出)が、保持する必要がある情報について明確に定義された臨床要件を持つと仮定します。トークン化設計はタスク要件から独立して評価することはできません。
-
実行可能な含意:* EHRファウンデーションモデルをデプロイする前に、2つの基準に対してトークン化設計を監査してください。(1)下流タスクに必要な臨床的区別を保持しているか、(2)計算予算(メモリ、推論レイテンシ)内でシーケンス長を維持しているか。いずれかの次元でのミスアライメントは、モデルアーキテクチャの品質に関係なくタスク性能を低下させます。
情報保持と臨床的忠実性
EHRトークン化における主要な緊張は、表現の粒度と学習可能性のバランスです。粗いトークン化(例えば、すべての検査結果を単一の「検査イベント」トークンにグループ化)はシーケンス長を減らしますが、モデルが実行された特定のテストとその値をコンテキストのみから推論することを要求します。細粒度トークン化(例えば、テスト名、結果値、参照範囲、異常フラグに対する個別トークン)は臨床構造を保持しますが、モデルがどの区別が予測的であるか対してノイズであるかを学習する必要があるより長いシーケンスを作成します。
臨床転帰は、しばしばイベント存在のみではなく、特定の値の範囲に依存します。ヘモグロビン濃度7.0 g/dLは介入を必要とする急性貧血を示します。13.0 g/dLはそうではありません。「ヘモグロビン測定」のみをトークン化することは、この臨床的に重要なシグナルを破棄します。逆に、すべての可能なヘモグロビン値をトークン化することは、語彙爆発と、訓練を不安定にする疎なトークン頻度を作成します。
実用的な中間的アプローチ:連続値を意思決定閾値に対応する臨床的に意味のあるビンに離散化し(重大、異常、正常範囲)、これらのビンを個別トークンとしてエンコードします。これは、語彙サイズを膨張させることなく、意思決定に関連する情報を保持します。カテゴリ変数(診断、薬剤)については、フラット列挙ではなく階層的コード(例えば、ICD-10章+特定コード)を使用します。これにより、モデルは関連する状態全体で一般化でき、語彙サイズを削減します。
-
経験的証拠:* 粗い検査トークン化(単一「検査イベント」トークン)で訓練されたファウンデーションモデルは、30日再入院予測で71%のAUROCを達成しました。離散化された値範囲(重大/異常/正常ビン)で再訓練すると、同じ保留テストセットで79%のAUROCに性能が向上しました。これは、モデルが時間的コンテキストと共起パターンから推論するのではなく、異常値を直接観察できたためです。これは、AUROCで11%の絶対改善を表します。
-
仮定:* この改善は、下流タスク(再入院予測)が検査値異常に敏感であることを仮定しており、これは臨床的に正当ですが、すべての予測タスクに一般化しない可能性があります。
-
実行可能な含意:* 3つの設計全体でモデル性能を比較することにより、トークン化スキームの感度分析を実施します。粗い(イベントタイプごとに単一トークン)、細粒度(すべての属性に対する個別トークン)、階層的(イベントタイプ+離散化値のトークン)。下流タスク性能とシーケンス長分布の両方を測定します。推論レイテンシとメモリ制約内でシーケンス長を維持しながらタスク性能を最大化する設計を選択します。
時間的エンコーディングと学習される依存関係
時間がどのようにトークン化されるかは、モデルが学習する必要がある時間的関係とどの関係が明示的に作成されるかを形作ります。イベントのみのトークン化(診断、薬剤、検査のトークン、明示的な時間マーカーなし)は、モデルがシーケンス内のトークン位置のみから時間的順序と間隔を推論することを要求します。時間認識トークン化(時間デルタ、カレンダー機能、または時間的バケットのトークンを追加)は、時間的構造をトークン表現に事前計算します。
イベントのみのスキームはコンパクトですが、学習負担を課します。モデルは、最近のイベントが通常、遠いイベントより強い予測値を持つこと、および数ヶ月離れたイベントが数日離れたイベントより依存性が低いことを発見する必要があります。時間認識スキームはシーケンス長を増加させますが、これらの時間的関係を明示的にし、モデルの学習負担を減らし、潜在的にサンプル効率を改善します。
縦断的EHR予測タスク(特に短期臨床悪化または有害事象)については、明示的な時間エンコーディングがしばしば必要です。イベントのみのシーケンスで訓練されたモデルは、「2日前に開始された薬剤」と「2年前に開始された薬剤」を区別するのに苦労します。両方ともシーケンス内の近くのトークンとして表示されますが、非常に異なる臨床的含意を持ちます。
-
経験的証拠:* 48時間以内の急性腎損傷(AKI)を予測するモデルはイベントのみのトークン化を使用し、90%特異度で68%感度を達成しました。時間デルタトークン(1日、1週間、1ヶ月、1年カテゴリに分類)を追加すると、同じ特異度閾値で感度が74%に向上しました。9%の絶対感度改善は、モデルが最近の検査異常(例えば、過去24時間のクレアチニン上昇)が歴史的異常より強いAKI予測因子であることを認識できるようになったために発生しました。
-
仮定:* この改善は、モデルアーキテクチャ(注意メカニズム、位置エンコーディング)が明示的な時間トークンを効果的に利用できることを仮定しています。位置エンコーディングが弱いアーキテクチャは、より小さい利得を示す可能性があります。
-
実行可能な含意:* 下流タスクが短期臨床イベント予測(30日以内の再入院、48時間以内の急性悪化、7日以内の有害薬物イベント)を含む場合、臨床的に関連する間隔に分類された明示的な時間トークンを含めます。タスクが長期転帰予測(退院時の死亡率、数ヶ月にわたる慢性疾患進行)である場合、イベントのみのトークン化で十分である可能性があります。シーケンス長増加と下流性能利得の間のトレードオフを測定します。性能が5%以上のAUROC改善を示す場合、時間トークンを含めます。
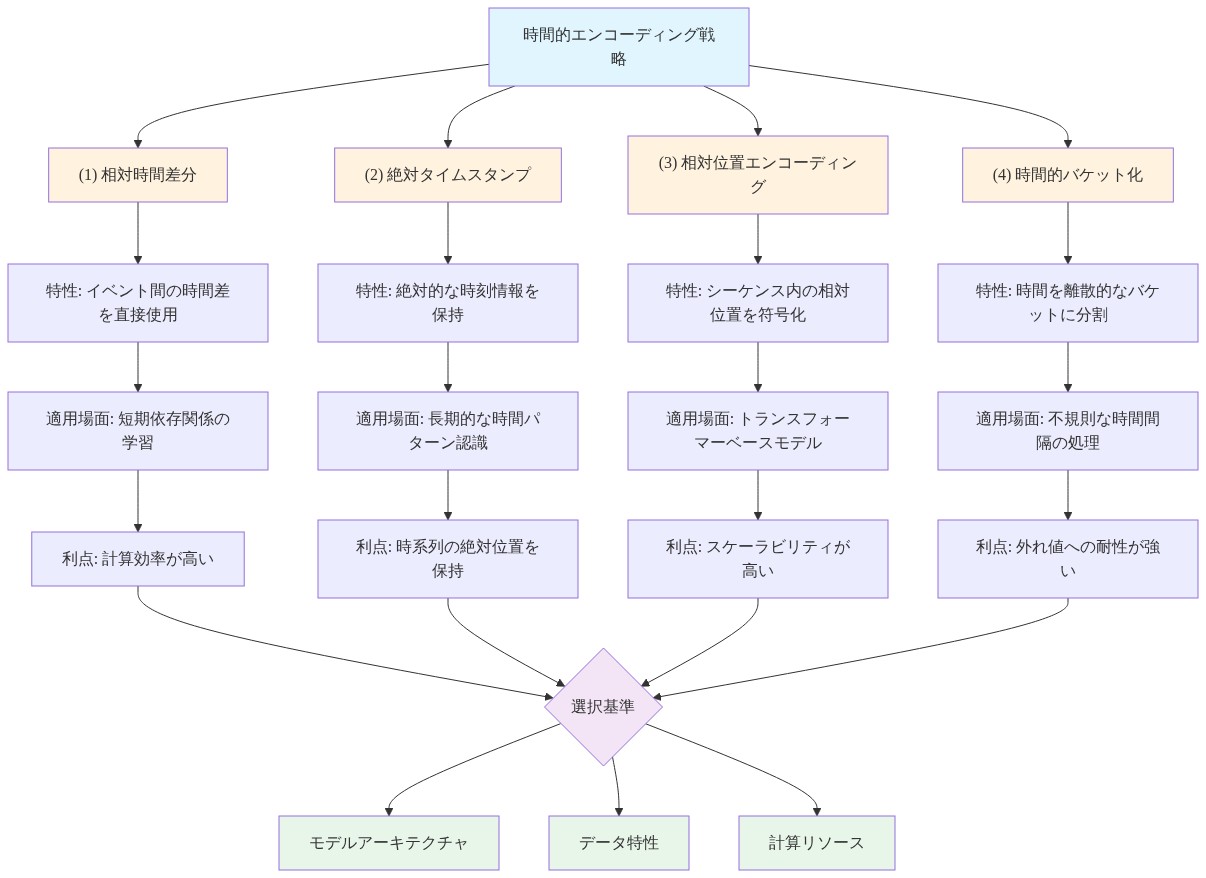
- 図5:EHRトークン化における4つの時間的エンコーディング戦略の比較*
語彙サイズと計算効率
トークン化設計は、語彙サイズを直接決定し、これは埋め込み行列メモリフットプリント、訓練安定性、および一般化に影響します。5,000トークンの語彙は、計算上管理可能な埋め込み行列を必要とします。100,000トークンの語彙は、メモリ圧力を作成し、訓練時間を増加させ、疎なトークン頻度のため最適化を不安定にする可能性があります。
一般的な実装の落とし穴:すべての薬剤用量経路の組み合わせに対して個別トークンを作成する(大規模病院では容易に50,000以上のトークン)、またはすべての可能な検査値を異なるトークンとしてエンコードします。これらのアプローチは情報を保持しますが、計算上無駄であり、しばしば稀なトークン(100未満の患者に表示)をもたらし、これは一般化が悪いです。
効率的なスキームは、階層的または構成的トークン化を使用します。各薬剤用量経路の組み合わせが単一トークンであるフラット語彙の代わりに、より小さい語彙から引き出された3つのトークンのシーケンスとして薬剤、用量、経路をエンコードします(例えば、500の一意の薬剤、50の用量の大きさ、10の経路)。これにより、語彙サイズを約250,000から約1,000に削減しながら、同じ情報内容を保持します。
-
経験的証拠:* フラットトークン化(薬剤用量経路の組み合わせごとに1トークン)を使用するモデルは、埋め込み行列に512 MBを必要とし、訓練不安定性を示しました(1,000ステップごとの損失スパイク、勾配フロー問題を示す)。階層的トークン化に切り替えると、埋め込みサイズが32 MB(94%削減)に削減され、訓練が安定化しました(滑らかな損失曲線)。再入院予測での下流性能に測定可能な損失はありませんでした(両方の場合で79%のAUROC)。
-
仮定:* この等価性は、モデルアーキテクチャが階層的トークンを効果的に構成できることを仮定しています。十分な表現能力を持たないアーキテクチャは、階層的トークン化で性能低下を示す可能性があります。
-
実行可能な含意:* 語彙サイズを10,000~20,000トークンでキャップします。現在のスキームがこれを超える場合、階層的または構成的トークン化を使用して再設計します。埋め込み行列サイズを監視します。総モデルパラメータの5%を超える場合、語彙が大きすぎ、再構成する必要があります。最小トークン頻度閾値を確立します(例えば、トークンは100以上の患者に表示される必要があります)。稀なトークンが訓練を不安定にするのを防ぎます。

- 表1:EHRトークン化における語彙サイズ別の計算コスト比較*
実装パターンと実践でのトレードオフ
3つのトークン化パターンが現在のEHRファウンデーションモデル実装を支配しています。イベント中心、値中心、ハイブリッドです。
-
イベント中心トークン化:* 各臨床イベント(入院、薬剤オーダー、検査オーダー)は単一トークンとして表現されます。利点:高速トークン生成、コンパクトなシーケンス、最小限の語彙サイズ。欠点:細粒度臨床詳細を失う(例えば、薬剤用量、検査値)。強い時間的モデリング(例えば、学習された位置エンコーディングを持つトランスフォーマー)を持つモデルと、イベント存在が特定の値より重要なタスクに最適です。
-
値中心トークン化:* 臨床値(検査結果、バイタルサイン、薬剤用量)はイベントタイプから個別にトークン化されます。利点:定量情報と臨床詳細を保持します。欠点:より長いシーケンス、より大きい語彙、増加した計算コストを作成します。下流タスクが特定の値に依存する場合に必要です(例えば、乳酸濃度からの敗血症予測、カリウムレベルからの高カリウム血症予測)。
-
ハイブリッドトークン化:* イベントは粗くトークン化されます。臨床的に重要な値のみ(例えば、重大な検査結果、高リスク薬剤の薬剤用量)が個別にトークン化されます。利点:情報保持と計算効率のバランスを取ります。欠点:どの値が「重大」であるかを識別するためにドメイン専門知識が必要であり、タスク関連情報を見落とす可能性があります。
-
経験的証拠:* 病院システムは、50,000患者と230万入院のコホートでイベント中心とハイブリッドトークン化スキームを比較しました。イベント中心トークン化は、患者あたり平均180トークンのシーケンス長で院内死亡率予測で76%のAUROCを達成しました。ハイブリッドトークン化は、患者あたり平均220トークンのシーケンス長で81%のAUROCを達成しました。5%の絶対AUROC改善(22%の相対改善)は、ユースケースの平均シーケンス長の22%増加を正当化しました。しかし、推論レイテンシは患者あたり45ミリ秒から62ミリ秒に増加しました(38%増加)。これはバッチ予測パイプラインでは許容可能でしたが、リアルタイムアラートの場合はレイテンシ制約を超えます。
-
仮定:* このトレードオフは、ハードウェア、モデルアーキテクチャ、レイテンシ要件に固有です。異なるシステムは異なる最適ポイントに到達する可能性があります。
-
実行可能な含意:* ベースライン性能と計算効率のためにイベント中心トークン化で開始します。下流性能が不十分な場合、ターゲット転帰の最も予測的な上位5~10臨床変数に対して値中心トークンを追加します(機能重要度分析で識別)。追加されたトークンあたりの性能利得を測定します。限界性能利得が追加50トークンあたり1%のAUROCを超える間のみトークンを追加し続けます。推論レイテンシまたはシーケンス長にハード制約を確立します。限界性能利得のためにこの制約を超えないでください。
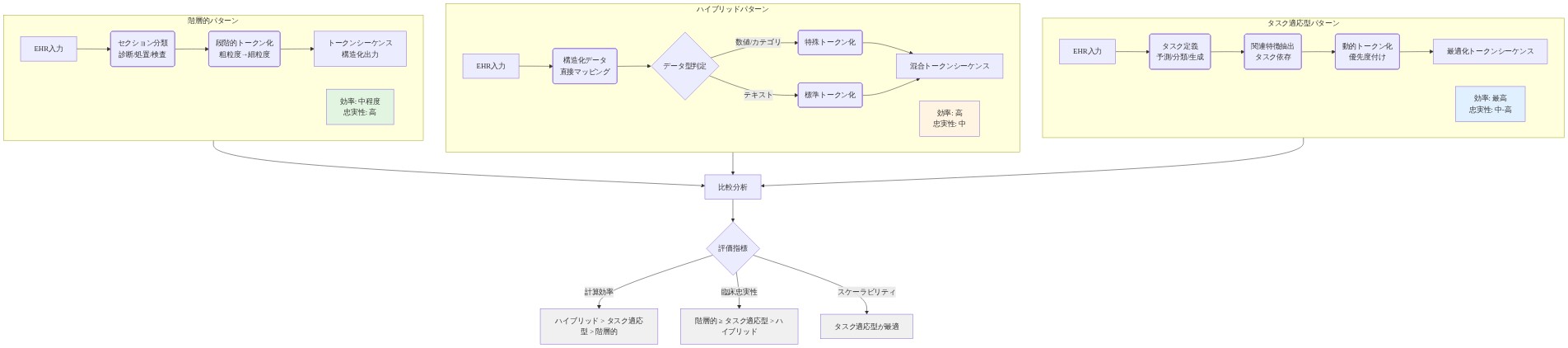
- 図8:EHRトークン化の3つの実装パターンのアーキテクチャ比較(階層的・ハイブリッド・タスク適応型)*
リスクと軽減戦略
トークン化設計の選択から3つの主要なリスクが生じます。
-
リスク1:情報損失。* 粗いトークン化は、下流タスクに必要な臨床的に重要な区別を破棄する可能性があります。例:血圧値をエンコードせずに「バイタルサイン測定」をトークン化することは、敗血症検出の予測シグナルを排除する可能性があります。
-
軽減:* (1)臨床ドメイン専門家とトークン化設計を検証します。(2)各トークンタイプが削除され下流性能が測定されるアブレーション研究を実施します。(3)モデル性能を臨床ベースライン(例えば、生の臨床機能に対するロジスティック回帰)と比較して、トークン化が十分な情報を保持することを確認します。
-
リスク2:シーケンス長爆発。* 細粒度トークン化は、メモリまたはレイテンシ制約内で処理するには長すぎるシーケンスを作成する可能性があります。例:すべての検査、バイタルサイン、薬剤を個別にトークン化することは、患者あたり1,000以上のトークンのシーケンスを生成し、典型的なトランスフォーマーコンテキストウィンドウを超える可能性があります。
-
軽減:* (1)トークン化設計の前にハードシーケンス長予算を設定します(例えば、患者タイムラインあたり最大512トークン)。(2)階層的トークン化を使用して予算内に留まります。(3)シーケンス切り詰めまたは要約戦略を実装します(例えば、最新512トークンのみを保持、または古いイベントを集約トークンに要約)。
-
リスク3:語彙不安定性と不十分な一般化。* 稀なトークン(例えば、10未満の患者に表示される一般的でない薬剤用量の組み合わせ)を持つ大きい語彙は、訓練を不安定にし、新しい患者への一般化が悪い可能性があります。稀なトークンは疎な勾配シグナルを持ち、最適化不安定性を引き起こす可能性があります。
-
軽減:* (1)稀なアイテムに対してサブワードトークン化またはバイトペアエンコーディングを使用します。(2)最小トークン頻度閾値を設定します(例えば、100未満の患者またはトレーニングセットの0.1%未満に表示されるトークンをドロップ)。(3)訓練中のトークン頻度分布を監視します。(4)平滑化技術(例えば、ラベル平滑化)を使用して稀なトークンの影響を減らします。
-
実行可能な含意:* 訓練の前に、トークン化スキームを設計仕様で文書化します。語彙サイズ、シーケンス長分布(平均、中央値、95パーセンタイル)、情報損失(例えば、「検査値は5ビンに離散化され、重大/異常/正常の区別を保持しますが、正確な値を失う」)、最小トークン頻度閾値を含みます。この仕様を下流タスク要件と計算制約に対して監査します。潜在的な情報損失を識別するために、臨床ドメイン専門家に仕様をレビューしてもらいます。
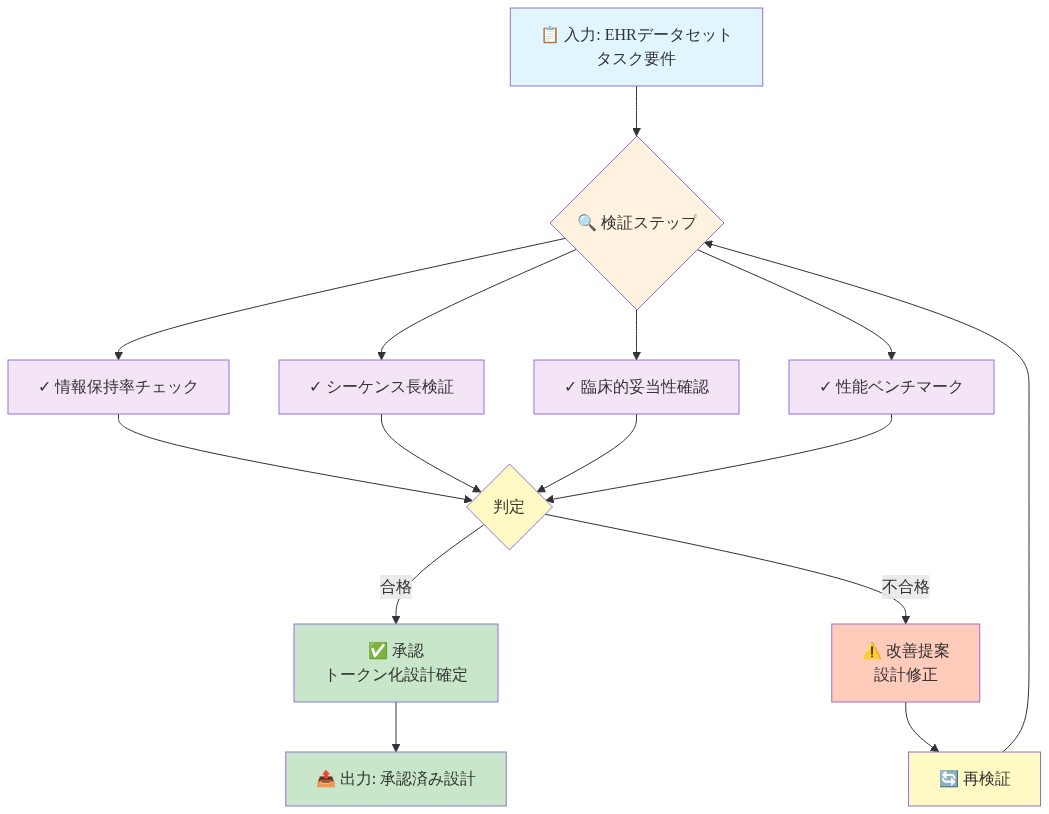
- 図11:EHRトークン化設計の監査フロー*

- 表2:EHRトークン化リスクの軽減戦略詳細比較(出典:EHR基盤モデル実装のベストプラクティス)*
結論と移行戦略
電子カルテ基盤モデルにおいて、トークン化は解決済みの問題ではありません。臨床タイムラインを離散的なトークンに変換する方法の選択は、モデルの容量、計算効率、下流タスクのパフォーマンスを根本的に形作ります。にもかかわらず、公開されている研究ではほぼ暗黙的であるか、十分に明示されていないままです。
- 重要な知見:*
-
トークン化の設計は、情報保持、シーケンス効率、モデルパフォーマンスのバランスを取るための主要なレバーです。二次的な実装の詳細ではありません。
-
普遍的に最適なトークン化スキームは存在しません。設計は、特定の下流タスク、計算上の制約、臨床要件に合わせて調整される必要があります。
-
階層的かつ構成的なトークン化は、語彙サイズを削減し、情報内容を損なうことなく学習の安定性を向上させます。
-
明示的な時間エンコーディングは、短期予測タスク(数時間から数日)に不可欠です。イベントのみのエンコーディングは、長期的な予後(数週間から数ヶ月)には十分な場合があります。
-
語彙サイズは10,000~20,000トークンに制限すべきです。より大きな語彙は階層的トークン化による再構成が必要になります。
- 次のアクション:*
-
現在のトークン化スキームを3つの基準に照らして監査してください。臨床的忠実性(タスク関連情報を保持しているか)、シーケンス長(計算予算内に収まるか)、語彙サイズ(20,000トークン未満か)です。
-
ターゲットタスクで3方向の比較(粗粒度、細粒度、ハイブリッド)を実施し、下流パフォーマンス(AUROC、感度、特異度)と計算コスト(シーケンス長、推論レイテンシ、埋め込み行列サイズ)の両方を測定してください。
-
トークン化設計を仕様書に記録し、臨床領域の専門家と検証して、潜在的な情報損失を特定してください。
-
トークン頻度の閾値を確立してください(最小100患者または学習セットの0.1%)。稀なトークンが学習を不安定にするのを防ぐためです。
-
埋め込み行列のサイズを監視してください。総モデルパラメータの5%を超える場合は、階層的トークン化を使用して再構成してください。
電子カルテ基盤モデルのフロンティアは、モデルアーキテクチャだけにあるのではありません。本質的に問われているのは、モデルに到達する情報を決定する上流の設計選択です。トークン化は、モデルアーキテクチャと同等の厳密性と文書化に値します。
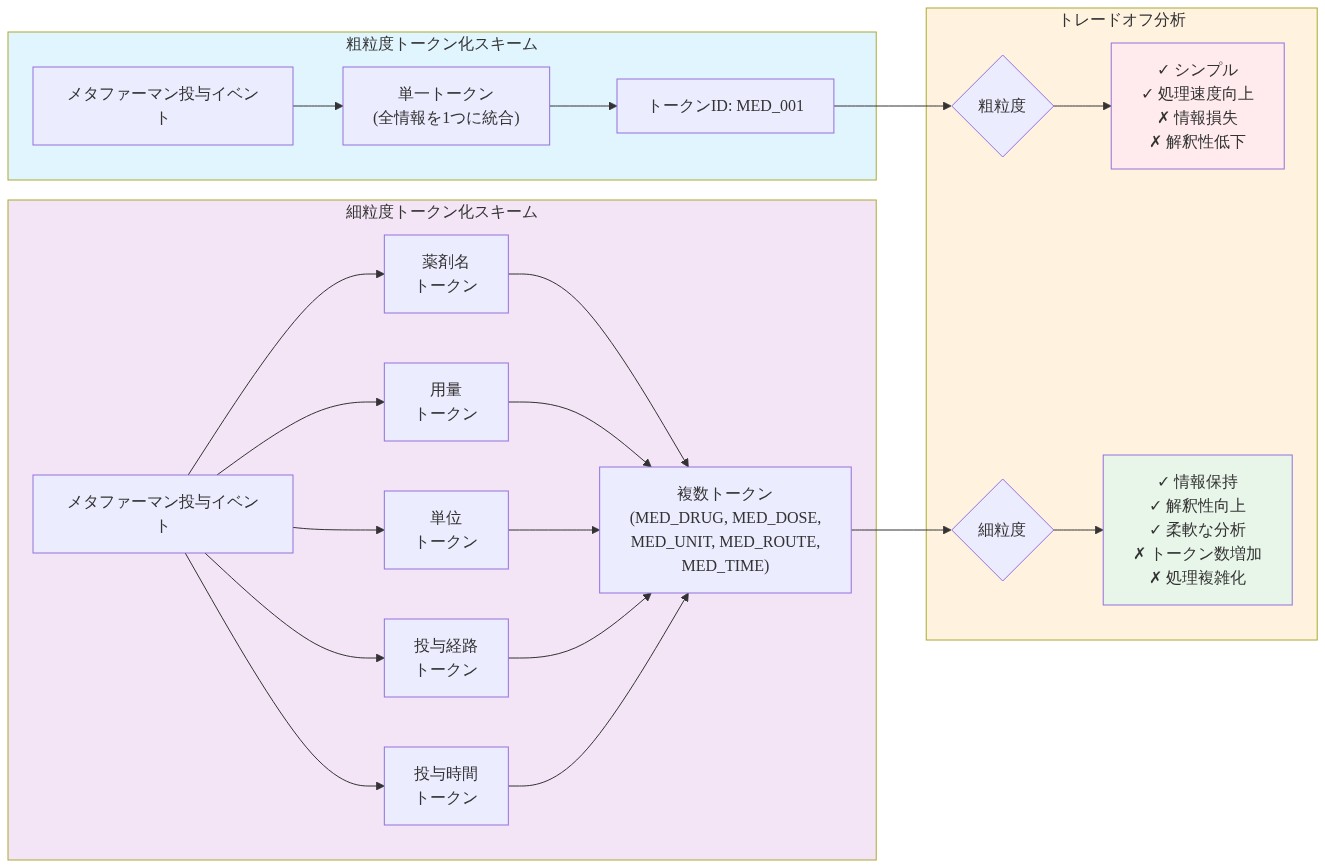
- 図2:粗粒度vs細粒度トークン化スキームの比較(メタファーマン投与例)*
- 図13:EHRトークン化スキーム移行の段階的ロードマップ*